Pandas Set_Option Method
Hôm nay, chúng ta sẽ xem xét cách sử dụng hàm “pd.set_option ()” để hiển thị tất cả các cột trong Khung dữ liệu Pandas khi trình bày nó trong công cụ Spyder của bạn. Để sử dụng “pd.set_option ()”, chúng tôi thực hiện theo cú pháp đã cho:

Hãy bắt đầu tìm hiểu khái niệm này với sự hỗ trợ của việc triển khai thực tế chương trình Python.
Ví dụ: Sử dụng phương pháp Set_Option của Pandas để hiển thị tất cả các cột
Trình diễn này là một hướng dẫn để hiển thị tất cả các cột trong DataFrame bằng cách sử dụng Pandas “set_option ()”. Chúng tôi sẽ làm rõ chi tiết từng bước để thực hiện phương pháp Python này.
Yêu cầu đầu tiên để triển khai thực tế tập lệnh Python là tìm ra công cụ tốt nhất để bạn thực thi chương trình của mình. Công cụ mà chúng tôi đã sử dụng cho minh họa của mình là công cụ “Spyder”. Chúng tôi đã khởi chạy công cụ và bắt đầu làm việc trên tập lệnh Python.
Bắt đầu với mã, ban đầu chúng ta cần nhập các thư viện điều kiện tiên quyết mà chúng ta cần trong chương trình này. Thư viện đầu tiên mà chúng tôi tải vào tệp Python của mình là thư viện Pandas vì các hàm mà chúng tôi sử dụng ở đây được cung cấp bởi Pandas. Chúng tôi đặt bí danh thư viện này là “pd”. Thư viện thứ hai mà chúng tôi đã tải là thư viện NumPy. NumPy (Numerical Python) là một gói tính toán số được phát triển dựa trên lập trình Python. Phần Nhập NumPy của mã hướng Python tích hợp mô-đun NumPy vào tệp Python hiện tại của bạn. Sau đó, phần “as np” của script sẽ hướng dẫn Python gán cho NumPy từ viết tắt “np”. Nó cho phép bạn sử dụng các phương thức NumPy bằng cách nhập “np. functions_name” thay vì NumPy.
Bây giờ, chúng ta bắt đầu với mã chính. Nhu cầu cơ bản và quan trọng nhất đối với chương trình của chúng tôi là Pandas DataFrame. Vì vậy, chúng tôi hiển thị tất cả các cột mà nó chứa. Bây giờ, hoàn toàn tùy thuộc vào bạn nếu bạn muốn tạo DataFrame với các giá trị được chỉ định hoặc nếu bạn cần nhập tệp CSV. Những gì chúng tôi chọn cho trường hợp này là tạo một DataFrame với các giá trị NaN. Chúng tôi đã gọi phương thức “pd.DataFrame ()” để tạo một DataFrame. Ở đây, chúng tôi đã cung cấp hai tham số - 'chỉ mục' và 'cột'. Đối số 'chỉ mục' đề cập đến các hàng có nghĩa là chúng tôi đặt các hàng cho DataFrame.
Chúng tôi đã gán tham số “index” và hàm NumPy “np.arange () với số giá trị là“ 6 ”. Nó tạo ra sáu hàng cho DataFrame. Nó điền vào tất cả các mục nhập với giá trị NaN vì chúng tôi không cung cấp cho nó bất kỳ giá trị nào. Đối số 'cột', như tên chỉ định, được sử dụng để đặt các cột cho DataFrame. Nó cũng được gán hàm “np.arange ()” với số giá trị “25” cho các cột. Do đó, nó tạo 25 cột cho DataFrame.
Do đó, khi chúng ta gọi hàm “pd.DataFrame ()”, chúng ta có một DataFrame với 25 cột và 6 hàng chứa đầy giá trị rỗng. Để bảo tồn DataFrame này, chúng tôi bắt buộc phải xây dựng một đối tượng DataFrame để lưu trữ nội dung của nó. Do đó, chúng tôi đã tạo một đối tượng DataFrame “ngẫu nhiên” và gán cho nó kết quả mà chúng tôi nhận được từ phương thức “pd.DataFrame ()”. Bây giờ, bạn chắc chắn muốn thấy DataFrame được tạo. Python cung cấp cho chúng ta một phương thức để xem kết quả đầu ra trên màn hình là hàm “print ()”. Chúng tôi gọi phương thức này bằng cách chuyển đối tượng DataFrame “random” làm tham số của nó.
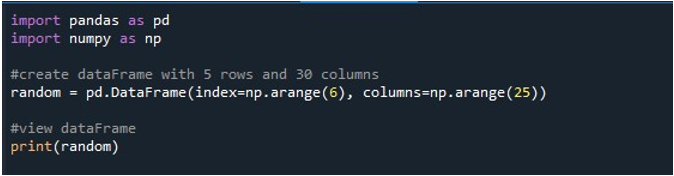
Khi chúng tôi thực thi đoạn mã này, chúng tôi nhận được DataFrame của chúng tôi với các giá trị NaN được hiển thị trên thiết bị đầu cuối. Ở đây, chúng ta có thể quan sát thấy một số cột đầu tiên và chỉ một số cột cuối cùng được hiển thị. Tất cả các cột ở giữa đều bị cắt bớt. Theo mặc định, nó ẩn một số hàng và cột để tránh tạo ra sự khó chịu cho người dùng bằng cách hiển thị các tập dữ liệu khổng lồ.
Bạn thậm chí có thể kiểm tra tổng số cột trong DataFrame bằng cách sử dụng hàm “len ()” của Pandas. Viết hàm “len ()” trên giao diện điều khiển của công cụ “Spyder” của bạn. Viết tên DataFrame giữa dấu ngoặc đơn với thuộc tính “.columns”. Nó trả về cho chúng tôi tổng độ dài của các cột trong DataFrame của bạn.

Nó trả về độ dài DataFrame của chúng ta là 25.
Bây giờ, nhiệm vụ tiếp theo và cốt lõi là thay đổi tùy chọn mặc định để hiển thị đầu ra. Có thể có những trường hợp bạn muốn xem toàn bộ DataFrame trên thiết bị đầu cuối. Do các giá trị mặc định, nhiều mục nhập bị cắt bớt gây ra sự thất vọng cho người dùng. Bạn sẽ tìm hiểu ở đây cách khắc phục vấn đề này. Pandas cung cấp cho chúng tôi một hàm “pd.set_option ()” để thay đổi cài đặt hiển thị mặc định. Ngay sau khi hiển thị DataFrame trên bảng điều khiển, chúng tôi gọi phương thức “pd.set_option ()”. Chúng tôi chỉ định tham số giữa các dấu ngoặc đơn của hàm này mà chúng tôi cần sử dụng để hiển thị tất cả các cột của DataFrame.
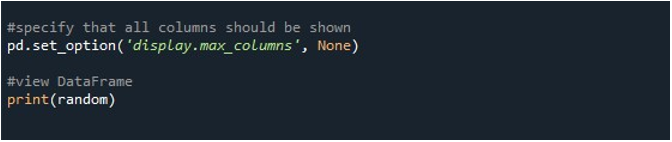
Ở đây, chúng tôi đã sử dụng “display.max_columns” để hiển thị các cột tối đa trong DataFrame của chúng tôi. Chúng tôi cũng có thể xác định giá trị cho tham số này, tức là các cột tối đa mà bạn muốn hiển thị. Mặt khác, chúng tôi đặt “display.max_columns” thành “Không”, hiển thị tất cả các cột từ DataFrame với độ dài tối đa. Cuối cùng, chúng tôi sử dụng hàm “print ()” để hiển thị DataFrame kết quả với tất cả các cột hiển thị trên thiết bị đầu cuối.
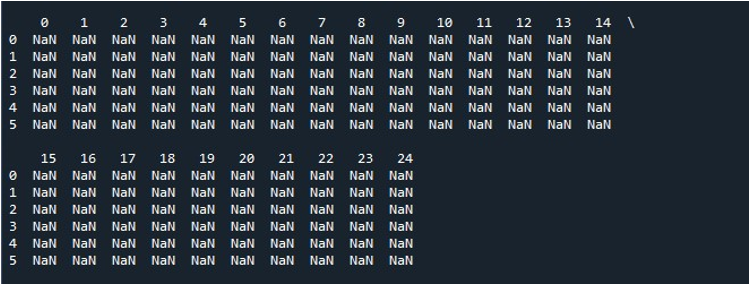
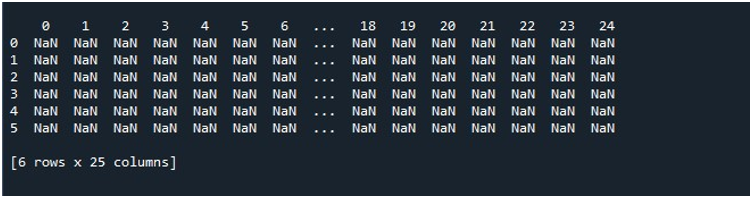
Khi chúng tôi nhấn vào tùy chọn “Chạy tệp” trên công cụ “Spyder”, chúng tôi có thể xem một DataFrame đang được trưng bày. DataFrame này có sáu hàng và số cột mà nó chứa là 25. Không có cột nào bị cắt bớt vì chức năng “pd.set_option ()” với độ dài cột tối đa được bật ngay bây giờ.
Chúng tôi thậm chí có thể đặt lại tùy chọn hiển thị vì khi chúng tôi đặt độ dài hiển thị thành tối đa, nó sẽ tiếp tục hiển thị DataFrames với tất cả các cột trong tệp Python cụ thể đó. Đối với điều này, chúng tôi sử dụng Pandas “pd.reset_option ()”. Chúng tôi gọi hàm này và cung cấp “display.max_columns” làm tham số của hàm này.

Điều này giúp chúng tôi cài đặt hiển thị ban đầu cho DataFrame được cung cấp.
Sự kết luận
Để xem kết quả đầu ra hoàn chỉnh trên thiết bị đầu cuối với một tập dữ liệu khổng lồ đôi khi chúng tôi gặp rắc rối khi cài đặt mặc định của công cụ trái ngược với nhu cầu của người dùng. Để giải quyết sự thất bại này, Pandas cung cấp cho chúng ta phương thức “pd.set_option ()”. Trong hướng dẫn học tập này, chúng tôi đã giới thiệu cho bạn phương pháp này và sự cần thiết phải sử dụng nó. Chúng tôi đã chứng minh chủ đề bằng các mã mẫu Python được biên dịch và thực thi thực tế. Chúng tôi đưa ra kết quả của hình minh họa được thực hiện trên 'Spyder'. Chúng tôi đã giải thích cách hiển thị tất cả các cột của DataFrame trên bảng điều khiển bằng cách thay đổi cài đặt mặc định cũng như đặt lại tất cả cài đặt về ban đầu. Tập trung hoàn toàn vào việc triển khai thực tế của mô-đun cho phép bạn sử dụng nó bất cứ khi nào bạn gặp phải sự cố như vậy.