Tối ưu hóa mã Python bằng các công cụ định hình
Thiết lập Google Colab để tối ưu hóa mã Python bằng các công cụ định hình, chúng tôi bắt đầu bằng cách thiết lập môi trường Google Colab. Nếu chúng ta chưa quen với Colab thì đây là một nền tảng dựa trên đám mây mạnh mẽ, thiết yếu cung cấp quyền truy cập vào sổ ghi chép Jupyter và một loạt thư viện Python. Chúng tôi truy cập Colab bằng cách truy cập (https://colab.research.google.com/) và tạo một sổ ghi chép Python mới.
Nhập thư viện hồ sơ
Sự tối ưu hóa của chúng tôi dựa vào việc sử dụng thành thạo các thư viện hồ sơ. Hai thư viện quan trọng trong ngữ cảnh này là cProfile và line_profiler.
nhập khẩu hồ sơ c
nhập khẩu line_profiler
Thư viện “cProfile” là một công cụ Python tích hợp để định hình mã, trong khi “line_profiler” là một gói bên ngoài cho phép chúng tôi đi sâu hơn nữa, phân tích từng dòng mã.
Trong bước này, chúng ta tạo một tập lệnh Python mẫu để tính toán dãy Fibonacci bằng hàm đệ quy. Hãy phân tích quá trình này sâu hơn. Dãy số Fibonacci là một tập hợp các số trong đó mỗi số liên tiếp bằng tổng của hai số đứng trước nó. Nó thường bắt đầu bằng 0 và 1, vì vậy chuỗi trông giống như 0, 1, 1, 2, 3, 5, 8, 13, 21, v.v. Đó là một chuỗi toán học thường được sử dụng làm ví dụ trong lập trình do tính chất đệ quy của nó.
Chúng tôi định nghĩa một hàm Python có tên là “Fibonacci” trong hàm Fibonacci đệ quy. Hàm này lấy số nguyên “n” làm đối số, biểu thị vị trí trong dãy Fibonacci mà chúng ta muốn tính toán. Ví dụ: chúng ta muốn xác định số thứ năm trong dãy Fibonacci nếu “n” bằng 5.
chắc chắn fibonacci ( N ) :
Tiếp theo, chúng tôi thiết lập một trường hợp cơ sở. Trường hợp cơ bản trong đệ quy là trường hợp kết thúc cuộc gọi và trả về một giá trị được xác định trước. Trong dãy Fibonacci, khi “n” bằng 0 hoặc 1 thì chúng ta đã biết trước kết quả. Các số Fibonacci thứ 0 và thứ 1 lần lượt là 0 và 1.
nếu như N <= 1 :trở lại N
Câu lệnh “if” này xác định xem “n” có nhỏ hơn hoặc bằng 1 hay không. Nếu đúng như vậy, chúng ta sẽ trả về chính “n” vì không cần đệ quy thêm.
Tính toán đệ quy
Nếu “n” vượt quá 1, chúng ta tiến hành tính toán đệ quy. Trong trường hợp này, chúng ta cần tìm số Fibonacci thứ “n” bằng cách tính tổng các số Fibonacci thứ “(n-1)” và “(n-2)”. Chúng tôi đạt được điều này bằng cách thực hiện hai lệnh gọi đệ quy trong hàm.
khác :trở lại fibonacci ( N - 1 ) + fibonacci ( N - 2 )
Ở đây, “fibonacci(n – 1)” tính số Fibonacci thứ “(n-1)”, và “fibonacci(n – 2)” tính số Fibonacci thứ “(n-2)”. Chúng ta cộng hai giá trị này để có được số Fibonacci mong muốn ở vị trí “n”.
Tóm lại, hàm “fibonacci” này tính toán đệ quy các số Fibonacci bằng cách chia bài toán thành các bài toán con nhỏ hơn. Nó thực hiện các cuộc gọi đệ quy cho đến khi đạt đến các trường hợp cơ bản (0 hoặc 1), trả về các giá trị đã biết. Đối với bất kỳ “n” nào khác, nó tính toán số Fibonacci bằng cách tính tổng kết quả của hai lệnh gọi đệ quy cho “(n-1)” và “(n-2)”.
Mặc dù cách triển khai này rất đơn giản để tính các số Fibonacci nhưng nó không hiệu quả nhất. Trong các bước sau, chúng tôi sẽ sử dụng các công cụ lập hồ sơ để xác định và tối ưu hóa các hạn chế về hiệu suất của nó để có thời gian thực thi tốt hơn.
Lập hồ sơ mã với CProfile
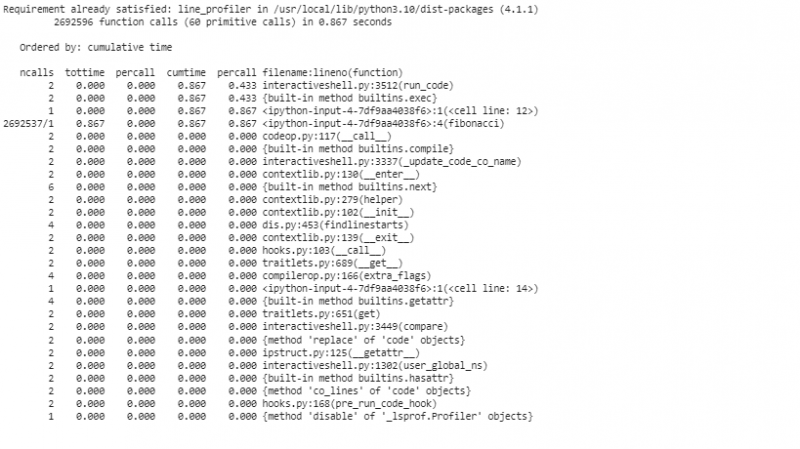
Bây giờ, chúng tôi lập hồ sơ cho hàm “fibonacci” của mình bằng cách sử dụng “cProfile”. Bài tập lập hồ sơ này cung cấp thông tin chuyên sâu về thời gian mà mỗi lệnh gọi hàm sử dụng.
cprofiler = cProfile. Hồ sơ ( )cprofiler. cho phép ( )
kết quả = fibonacci ( 30 )
cprofiler. vô hiệu hóa ( )
cprofiler. print_stats ( loại = 'tích lũy' )
Trong phân đoạn này, chúng tôi khởi tạo đối tượng “cProfile”, kích hoạt hồ sơ, yêu cầu chức năng “fibonacci” với “n=30”, hủy kích hoạt hồ sơ và hiển thị số liệu thống kê được sắp xếp theo thời gian tích lũy. Hồ sơ ban đầu này cung cấp cho chúng tôi cái nhìn tổng quan cấp cao về chức năng nào tiêu tốn nhiều thời gian nhất.
! cài đặt pip line_profilernhập khẩu hồ sơ c
nhập khẩu line_profiler
chắc chắn fibonacci ( N ) :
nếu như N <= 1 :
trở lại N
khác :
trở lại fibonacci ( N - 1 ) + fibonacci ( N - 2 )
cprofiler = cProfile. Hồ sơ ( )
cprofiler. cho phép ( )
kết quả = fibonacci ( 30 )
cprofiler. vô hiệu hóa ( )
cprofiler. print_stats ( loại = 'tích lũy' )
Để cấu hình từng dòng mã bằng line_profiler nhằm phân tích chi tiết hơn, chúng tôi sử dụng “line_profiler” để phân đoạn dòng mã của mình theo dòng. Trước khi sử dụng “line_profiler”, chúng ta phải cài đặt gói trong kho Colab.
! cài đặt pip line_profilerBây giờ chúng ta đã có sẵn “line_profiler”, chúng ta có thể áp dụng nó cho hàm “fibonacci” của mình:
%load_ext line_profilerchắc chắn fibonacci ( N ) :
nếu như N <= 1 :
trở lại N
khác :
trở lại fibonacci ( N - 1 ) + fibonacci ( N - 2 )
%lprun -f fibonacci fibonacci ( 30 )
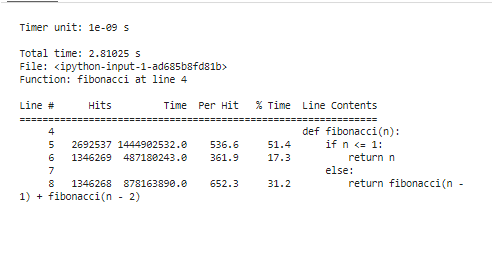
Đoạn mã này bắt đầu bằng cách tải tiện ích mở rộng “line_profiler”, xác định hàm “fibonacci” của chúng tôi và cuối cùng sử dụng “%lprun” để lập cấu hình hàm “fibonacci” với “n=30”. Nó cung cấp phân đoạn thời gian thực thi theo từng dòng, xác định chính xác nơi mã của chúng tôi sử dụng tài nguyên.
Sau khi chạy các công cụ lập hồ sơ để phân tích kết quả, nó sẽ hiển thị một loạt số liệu thống kê cho thấy các đặc điểm hiệu suất mã của chúng tôi. Những thống kê này liên quan đến tổng thời gian sử dụng trong mỗi chức năng và thời lượng của mỗi dòng mã. Ví dụ: chúng ta có thể phân biệt rằng hàm Fibonacci cần nhiều thời gian hơn một chút để tính toán lại các giá trị giống nhau nhiều lần. Đây là tính toán dư thừa và là lĩnh vực rõ ràng có thể áp dụng tối ưu hóa, thông qua ghi nhớ hoặc bằng cách sử dụng các thuật toán lặp.
Bây giờ, chúng tôi thực hiện tối ưu hóa khi chúng tôi xác định được mức tối ưu hóa tiềm năng trong hàm Fibonacci của mình. Chúng tôi nhận thấy rằng hàm này tính toán lại các số Fibonacci giống nhau nhiều lần, dẫn đến sự dư thừa không cần thiết và thời gian thực hiện chậm hơn.
Để tối ưu hóa điều này, chúng tôi thực hiện việc ghi nhớ. Ghi nhớ là một kỹ thuật tối ưu hóa bao gồm việc lưu trữ các kết quả được tính toán trước đó (trong trường hợp này là các số Fibonacci) và sử dụng lại chúng khi cần thay vì tính toán lại chúng. Điều này làm giảm các phép tính dư thừa và cải thiện hiệu suất, đặc biệt đối với các hàm đệ quy như dãy Fibonacci.
Để triển khai tính năng ghi nhớ trong hàm Fibonacci, chúng ta viết đoạn mã sau:
# Từ điển lưu trữ số Fibonacci được tính toánfib_cache = { }
chắc chắn fibonacci ( N ) :
nếu như N <= 1 :
trở lại N
# Kiểm tra xem kết quả đã được lưu vào bộ đệm chưa
nếu như N TRONG fib_cache:
trở lại fib_cache [ N ]
khác :
# Tính toán và lưu trữ kết quả
fib_cache [ N ] = fibonacci ( N - 1 ) + fibonacci ( N - 2 )
trở lại fib_cache [ N ] ,
Trong phiên bản sửa đổi này của hàm “fibonacci”, chúng tôi giới thiệu từ điển “fib_cache” để lưu trữ các số Fibonacci được tính toán trước đó. Trước khi tính số Fibonacci, chúng tôi kiểm tra xem nó đã có trong bộ đệm chưa. Nếu đúng như vậy, chúng tôi sẽ trả về kết quả được lưu trong bộ nhớ đệm. Trong mọi trường hợp khác, chúng tôi tính toán nó, giữ nó trong bộ đệm và sau đó trả lại.
Lặp lại hồ sơ và tối ưu hóa
Sau khi triển khai tối ưu hóa (ghi nhớ trong trường hợp của chúng tôi), điều quan trọng là phải lặp lại quy trình lập hồ sơ để biết tác động của các thay đổi và đảm bảo rằng chúng tôi đã cải thiện hiệu suất của mã.
Hồ sơ sau khi tối ưu hóa
Chúng ta có thể sử dụng cùng các công cụ lập hồ sơ, “cProfile” và “line_profiler”, để lập hồ sơ cho hàm Fibonacci được tối ưu hóa. Bằng cách so sánh kết quả lập hồ sơ mới với kết quả trước đó, chúng tôi có thể đo lường hiệu quả tối ưu hóa của mình.
Đây là cách chúng ta có thể cấu hình chức năng “fibonacci” được tối ưu hóa bằng cách sử dụng “cProfile”:
cprofiler = cProfile. Hồ sơ ( )cprofiler. cho phép ( )
kết quả = fibonacci ( 30 )
cprofiler. vô hiệu hóa ( )
cprofiler. print_stats ( loại = 'tích lũy' )
Bằng cách sử dụng “line_profiler”, chúng tôi sẽ lập hồ sơ theo từng dòng:
%lprun -f fibonacci fibonacci ( 30 )Mã số:
# Từ điển lưu trữ số Fibonacci được tính toánfib_cache = { }
chắc chắn fibonacci ( N ) :
nếu như N <= 1 :
trở lại N
# Kiểm tra xem kết quả đã được lưu vào bộ đệm chưa
nếu như N TRONG fib_cache:
trở lại fib_cache [ N ]
khác :
# Tính toán và lưu trữ kết quả
fib_cache [ N ] = fibonacci ( N - 1 ) + fibonacci ( N - 2 )
trở lại fib_cache [ N ]
cprofiler = cProfile. Hồ sơ ( )
cprofiler. cho phép ( )
kết quả = fibonacci ( 30 )
cprofiler. vô hiệu hóa ( )
cprofiler. print_stats ( loại = 'tích lũy' )
%lprun -f fibonacci fibonacci ( 30 )
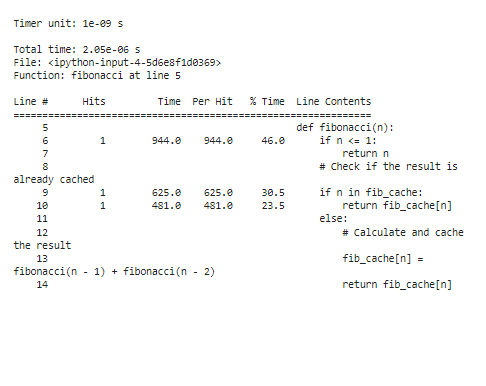
Để phân tích kết quả lập hồ sơ sau khi tối ưu hóa, thời gian thực hiện sẽ giảm đáng kể, đặc biệt đối với các giá trị “n” lớn. Nhờ tính năng ghi nhớ, chúng tôi nhận thấy rằng hàm này hiện tốn ít thời gian hơn để tính toán lại các số Fibonacci.
Các bước này rất cần thiết trong quá trình tối ưu hóa. Tối ưu hóa liên quan đến việc thực hiện những thay đổi sáng suốt đối với mã của chúng tôi dựa trên những quan sát thu được từ việc lập hồ sơ, trong khi việc lặp lại việc lập hồ sơ đảm bảo rằng việc tối ưu hóa của chúng tôi mang lại những cải thiện hiệu suất như mong đợi. Bằng cách lặp lại hồ sơ, tối ưu hóa và xác thực, chúng tôi có thể tinh chỉnh mã Python của mình để mang lại hiệu suất tốt hơn và nâng cao trải nghiệm người dùng cho các ứng dụng của chúng tôi.
Phần kết luận
Trong bài viết này, chúng tôi đã thảo luận về ví dụ trong đó chúng tôi đã tối ưu hóa mã Python bằng cách sử dụng các công cụ lập hồ sơ trong môi trường Google Colab. Chúng tôi đã khởi tạo ví dụ bằng cách thiết lập, nhập các thư viện hồ sơ cần thiết, viết mã mẫu, lập hồ sơ bằng cả “cProfile” và “line_profiler”, tính toán kết quả, áp dụng các tối ưu hóa và tinh chỉnh hiệu suất của mã nhiều lần.