Trong bài viết này, chúng ta sẽ thảo luận về cách phân bổ KHÁC BIỆT bộ nhớ thông qua “ pytorch_cuda_alloc_conf ' phương pháp.
Phương thức “pytorch_cuda_alloc_conf” trong PyTorch là gì?
Về cơ bản, “ pytorch_cuda_alloc_conf ” là một biến môi trường trong khung PyTorch. Biến này cho phép quản lý hiệu quả các tài nguyên xử lý có sẵn, điều đó có nghĩa là các mô hình chạy và tạo ra kết quả trong khoảng thời gian ít nhất có thể. Nếu không được thực hiện đúng cách, “ KHÁC BIỆT ” nền tảng tính toán sẽ hiển thị “ hết bộ nhớ ” lỗi và ảnh hưởng đến thời gian chạy. Các mô hình cần được đào tạo trên khối lượng dữ liệu lớn hoặc có “ kích thước lô ” có thể tạo ra lỗi thời gian chạy vì cài đặt mặc định có thể không đủ đối với chúng.
Các ' pytorch_cuda_alloc_conf ' biến sử dụng như sau ' tùy chọn ” để xử lý việc phân bổ tài nguyên:
- tự nhiên : Tùy chọn này sử dụng các cài đặt đã có sẵn trong PyTorch để phân bổ bộ nhớ cho mô hình đang thực hiện.
- max_split_size_mb : Nó đảm bảo rằng bất kỳ khối mã nào lớn hơn kích thước đã chỉ định sẽ không bị chia tách. Đây là một công cụ mạnh mẽ để ngăn chặn “ sự phân mảnh ”. Chúng tôi sẽ sử dụng tùy chọn này để trình diễn trong bài viết này.
- roundup_power2_divions : Tùy chọn này làm tròn kích thước phân bổ lên “ gần nhất sức mạnh của 2 ” chia theo megabyte (MB).
- roundup_bypass_threshold_mb: Nó có thể làm tròn kích thước phân bổ cho bất kỳ danh sách yêu cầu nào vượt quá ngưỡng được chỉ định.
- rác_collection_threshold : Nó ngăn chặn độ trễ bằng cách sử dụng bộ nhớ có sẵn từ GPU trong thời gian thực để đảm bảo rằng giao thức lấy lại toàn bộ không được khởi tạo.
Làm cách nào để phân bổ bộ nhớ bằng phương pháp “pytorch_cuda_alloc_conf”?
Bất kỳ mô hình nào có tập dữ liệu lớn đều yêu cầu phân bổ bộ nhớ bổ sung lớn hơn mức được đặt theo mặc định. Việc phân bổ tùy chỉnh cần được chỉ định dựa trên các yêu cầu về mô hình và tài nguyên phần cứng sẵn có.
Thực hiện theo các bước dưới đây để sử dụng “ pytorch_cuda_alloc_conf ” trong Google Colab IDE để phân bổ thêm bộ nhớ cho mô hình học máy phức tạp:
Bước 1: Mở Google Colab
Tìm kiếm Google hợp tác trong trình duyệt và tạo một “ Sổ tay mới ” để bắt đầu làm việc:
Bước 2: Thiết lập Mô hình PyTorch tùy chỉnh
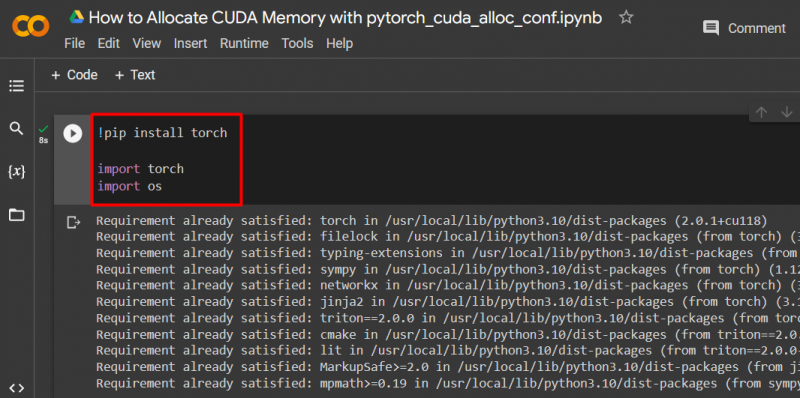
Thiết lập mô hình PyTorch bằng cách sử dụng “ !pip ” gói cài đặt để cài đặt “ ngọn đuốc ” thư viện và “ nhập khẩu ” lệnh nhập khẩu “ ngọn đuốc ' Và ' Bạn ” các thư viện vào dự án:
ngọn đuốc nhập khẩu
nhập khẩu chúng tôi
Các thư viện sau đây cần thiết cho dự án này:
- Ngọn đuốc – Đây là thư viện cơ bản làm nền tảng cho PyTorch.
- BẠN - Các ' hệ điều hành ” thư viện được sử dụng để xử lý các tác vụ liên quan đến biến môi trường như “ pytorch_cuda_alloc_conf ” cũng như thư mục hệ thống và quyền của tệp:
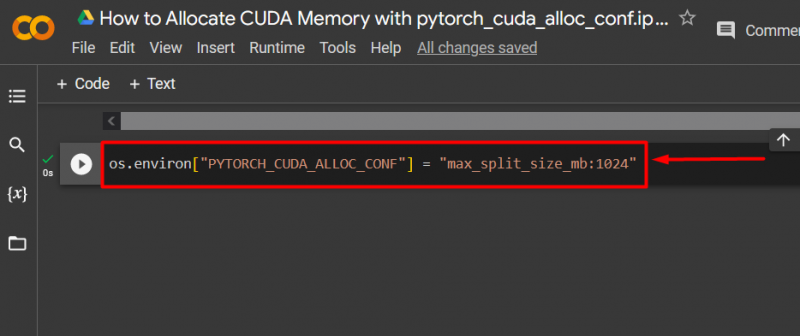
Bước 3: Phân bổ bộ nhớ CUDA
Sử dụng ' pytorch_cuda_alloc_conf ” phương pháp chỉ định kích thước phân chia tối đa bằng cách sử dụng “ max_split_size_mb ”:
Bước 4: Tiếp tục với Dự án PyTorch của bạn
Sau khi đã chỉ định “ KHÁC BIỆT ” phân bổ không gian với “ max_split_size_mb ” tùy chọn, hãy tiếp tục làm việc với dự án PyTorch như bình thường mà không sợ “ hết bộ nhớ ' lỗi.
Ghi chú : Bạn có thể truy cập sổ ghi chép Google Colab của chúng tôi tại đây liên kết .
Mẹo chuyên nghiệp
Như đã đề cập trước đó, “ pytorch_cuda_alloc_conf ” có thể thực hiện bất kỳ tùy chọn nào được cung cấp ở trên. Sử dụng chúng theo yêu cầu cụ thể của các dự án học sâu của bạn.
Thành công! Chúng tôi vừa trình bày cách sử dụng “ pytorch_cuda_alloc_conf ” phương thức để chỉ định một “ max_split_size_mb ” cho dự án PyTorch.
Phần kết luận
Sử dụng ' pytorch_cuda_alloc_conf ” để phân bổ bộ nhớ CUDA bằng cách sử dụng bất kỳ tùy chọn có sẵn nào theo yêu cầu của mô hình. Mỗi tùy chọn này đều nhằm mục đích giảm bớt một vấn đề xử lý cụ thể trong các dự án PyTorch để có thời gian chạy tốt hơn và hoạt động mượt mà hơn. Trong bài viết này, chúng tôi đã giới thiệu cú pháp sử dụng “ max_split_size_mb ” tùy chọn để xác định kích thước tối đa của phần phân chia.