keel (Knowledge Extraction based on Evolutionary Learning) là một công cụ phần mềm dựa trên Java chuyên thực hiện các thuật toán tiến hóa. Vì nó là một mã nguồn mở nên nó cung cấp rất nhiều thuật toán khám phá tri thức có thể được sử dụng trong các thử nghiệm hỗ trợ cộng đồng khai thác và phân tích dữ liệu. Nó cung cấp một giao diện người dùng đồ họa đơn giản và dễ sử dụng giúp giảm đáng kể độ phức tạp tổng thể của công cụ này. Hầu hết các công cụ tương tự trên thị trường đều yêu cầu người dùng tương tác với chúng bằng cách viết mã trong khi Keel loại bỏ yêu cầu này bằng cách cung cấp một GUI trực quan có thể được sử dụng bởi người mới bắt đầu cũng như các chuyên gia.
Keel cung cấp nhiều thuật toán dựa trên trí thông minh điện toán khác nhau bao gồm phân loại, hồi quy, trích xuất tính năng, phân tích mẫu, phân cụm, v.v. Với các mô hình chính được đưa ngay vào ứng dụng, Keel là một công cụ rất hữu ích khi thực hiện phân tích dữ liệu khám phá trên các tập dữ liệu thô. Giao diện kéo và thả đơn giản của nó kết hợp với việc sử dụng chức năng dễ dàng cho phép thử nghiệm khai thác dữ liệu nhanh chóng và hiệu quả cho cả mục đích giáo dục và nghiên cứu. Các công cụ như Keel đang ngày càng phổ biến vì cách tiếp cận đơn giản của chúng đối với các thực hành thuật toán phức tạp.
Cài đặt
Có hai cách chính để chúng ta có thể cài đặt keel trên bất kỳ máy Linux nào. Cái đầu tiên liên quan đến việc đi đến trang web keel và tải xuống phần mềm từ đó. Cái thứ hai mà chúng tôi sẽ làm theo trong hướng dẫn cài đặt này, yêu cầu chúng tôi tải xuống Keel bằng cách sử dụng quên đi công cụ tải xuống có sẵn cho người dùng Linux.
1. Chúng tôi bắt đầu bằng cách lấy quên đi trên máy Linux của chúng tôi.
Chạy lệnh sau để tải xuống wget bằng cách sử dụng đúng cách quản lý gói:
$ sudo cài đặt apt-get quên đi
Bạn sẽ thấy một đầu ra thiết bị đầu cuối tương tự:
2. Bây giờ chúng ta có quên đi công cụ được cài đặt trên máy Linux của chúng tôi, chúng tôi sử dụng nó để tải xuống keel dụng cụ.
Đây là liên kết mà chúng tôi chuyển đến wget.
Chạy lệnh sau trong thiết bị đầu cuối của bạn:
$ quên đi http: // sci2s.ugr.es / sống tàu / phần mềm / nguyên mẫu / phiên bản mở / Phần mềm- 2018 -04-09.zip
Bạn sẽ thấy một đầu ra tương tự trên thiết bị đầu cuối của mình:
Khi Keel tải xuống xong, chúng ta có thể tiếp tục với phần còn lại của quá trình cài đặt.
3. Bây giờ chúng tôi giải nén tệp nén mà chúng tôi đã tải xuống ở bước trước bằng công cụ Linux Unzip.
Chạy lệnh sau:
$ giải nén Phần mềm- 2018 -04-09.zip
Bạn sẽ thấy một đầu ra tương tự trong thiết bị đầu cuối:
4. Điều hướng vào thư mục Keel bằng cách chạy lệnh sau:
$ đĩa CD Phần mềm- 2018 -04-09 / các tài liệu / thí nghiệm / KEEL / quận /
5. Chạy lệnh sau để bắt đầu cài đặt:
$ java -cái lọ . / GraphInterKeel.jar
Với điều này, Keel sẽ có sẵn để bạn sử dụng trên máy Linux của mình.
Hướng dẫn sử dụng
Tương tác với keel ứng dụng thực sự dễ dàng và đơn giản. Hãy để chúng tôi bắt đầu bằng cách nhập khẩu Bộ dữ liệu mống mắt vào không gian làm việc của chúng tôi.
Khi chúng tôi nhập dữ liệu, công cụ này hiển thị cho chúng tôi cụm tổng thể của điểm dữ liệu trong tập dữ liệu. Nó cũng cho chúng ta thấy các lớp khác nhau có trong tập dữ liệu cùng với thông tin cơ bản như phạm vi số mà các điểm dữ liệu này kéo dài, phương sai tổng thể và giá trị trung bình mà nó hiện diện. Thông tin này cho phép người dùng hiểu rõ hơn về cách tiến hành chuẩn bị dữ liệu cho bất kỳ loại nhiệm vụ phân tích dữ liệu nào.
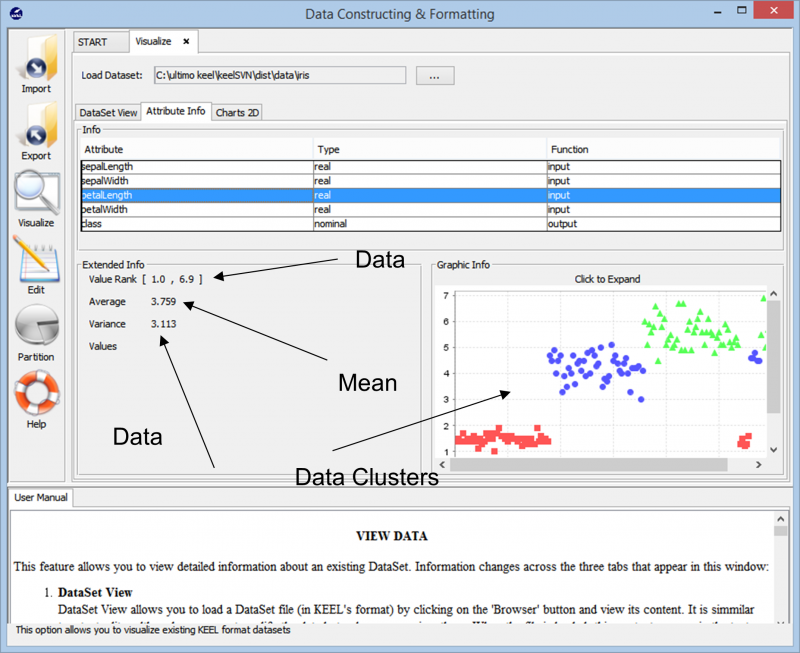
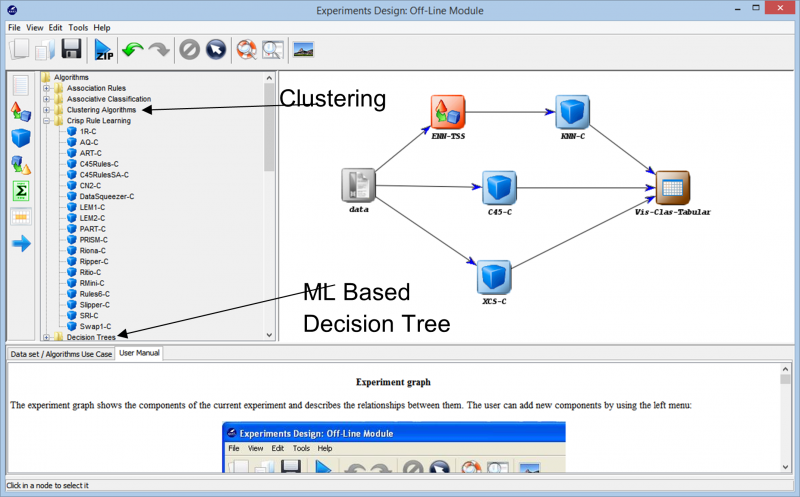
Tiếp tục tiến hành thử nghiệm, chúng tôi bắt gặp các kỹ thuật khác nhau có thể được sử dụng để tạo thử nghiệm của chúng tôi trên bất kỳ tập dữ liệu nào. Các thuật toán học tập khác nhau có thể được sử dụng trên dữ liệu của chúng tôi có thể được nhìn thấy trong hình ảnh sau đây. Tùy thuộc vào bản chất của tập dữ liệu và yêu cầu của thí nghiệm, các thuật toán khác nhau có thể được thực nghiệm.
Ví dụ: nếu bạn đang làm việc với dữ liệu chưa được gắn nhãn và phải tìm điểm tương đồng giữa các điểm dữ liệu khác nhau trong tập dữ liệu của mình, thì việc sử dụng thuật toán phân cụm từ nhiều tùy chọn khác nhau có sẵn có thể giúp bạn hiểu rõ hơn về các điểm dữ liệu. Điều này cuối cùng sẽ giúp bạn gắn nhãn và phân loại các điểm dữ liệu để có thể xây dựng thử nghiệm khi sử dụng các thuật toán học có giám sát toàn diện hơn.
Sự kết luận
Các keel nền tảng để phân tích dữ liệu là một nguồn tài nguyên tốt cho cả mục đích nghiên cứu và giáo dục. Giao diện người dùng đồ họa dễ sử dụng giúp người dùng hiểu rõ hơn các yêu cầu của dữ liệu cùng với việc cung cấp các tham chiếu hợp lý cho các kỹ thuật và thuật toán hữu ích hỗ trợ thêm cho người dùng trong quy trình làm việc của họ. Có nhiều loại thuật toán khác nhau thuộc các danh mục và kỹ thuật thuật toán khác nhau cho phép người dùng thử nghiệm nhiều hướng logic và so sánh các kết quả này để có thể đạt được giải pháp tối ưu nhất cho bất kỳ vấn đề nào.
Cách tiếp cận kéo và thả mã miễn phí của Keel để khai thác dữ liệu giúp ngay cả những người mới bắt đầu cũng có thể dễ dàng làm việc với các mô hình trí tuệ điện toán toàn diện. Điều này cung cấp cái nhìn sâu sắc về các tập dữ liệu phức tạp và kết quả là rút ra những suy luận hữu ích giúp giải quyết các vấn đề trong thế giới thực.