Quản lý lượng dữ liệu khổng lồ có thể là một nhiệm vụ khó khăn đối với người quản lý dữ liệu, chủ yếu nếu truy vấn hoặc kết quả quét của bạn chạy trên nhiều trang. Phân trang trong DynamoDB cho phép cơ sở dữ liệu xử lý lượng dữ liệu lớn bằng cách chia kết quả thành nhiều trang có thể quản lý. Bài viết này giải thích cách phân trang DynamoDB và cung cấp nhiều trường hợp sử dụng cũng như ví dụ khác nhau. Nó cũng nêu bật cách phân trang trong DynamoDB khác với phân trang trong các cơ sở dữ liệu khác.
Phân trang trong DynamoDB là gì?
Nói chung, phân trang, bắt nguồn từ các trang từ, là một kỹ thuật được cơ sở dữ liệu sử dụng để phân chia các bản ghi dữ liệu thành nhiều đoạn, phân đoạn hoặc trang. Và vì AWS DynamoDB hỗ trợ lưu trữ lượng lớn dữ liệu nên nó có khả năng phân trang đáng tin cậy.
Thành phần phân trang DynamoDB đảm bảo rằng bạn chỉ có thể truy xuất tối đa 1 GB dữ liệu cho mỗi lần quét hoặc truy vấn. Mặc dù đó là cài đặt mặc định nhưng bạn có thể thêm tham số giới hạn trong truy vấn để chỉ định giới hạn. Bạn có thể đặt thêm giới hạn cho số lượng bản ghi trong mỗi truy vấn quét.
Đáng chú ý là có một vài điểm khác biệt giữa phân trang trong DynamoDB và phân trang trong cơ sở dữ liệu SQL thông thường. Rõ ràng nhất là mỗi bản ghi được phân trang được truy xuất trong DynamoDB đều có chi phí trực tiếp, khiến đây trở thành quy tắc bất thành văn khi sử dụng phân trang trong DynamoDB. Tính năng này làm cho phân trang trở thành một yếu tố quan trọng trong việc hạn chế cả bản ghi được truy xuất và chi phí trực tiếp.
Cách sử dụng phân trang trong DynamoDB
1. Phân trang trong thao tác truy vấn
Trong DynamoDB, truy vấn chỉ trả về kết quả có kích thước tối đa 1 MB. Nhưng bạn có thể xác nhận một cách hiệu quả nếu có nhiều kết quả hơn bằng cách xem xét kỹ lưỡng kết quả của mình. Đáng chú ý, một kết quả thao tác truy vấn cấp thấp chứa một phần tử LastEvaluatedKey khác null để cho biết rằng có nhiều mục hơn liên quan đến truy vấn của bạn mà bạn nên truy xuất.
Kết quả không có phần tử LastEvaluatedKey có giá trị khác rỗng, ngụ ý rằng tất cả các mục khớp với truy vấn đều nằm trong giới hạn 1 MB và không có thêm mục nào để truy xuất. Tất nhiên, bạn cũng có thể đặt giới hạn cho số lượng mục trên mỗi kết quả. Xem lệnh mẫu sau:
truy vấn aws dynamodb \
--table-name MyTableName \
--key-điều kiện-biểu thức 'Khóa phân vùng = :pk \
--biểu thức-thuộc tính-giá trị '{' : pk ':{' S ':' a1234b '}},
--giới hạn 10 \
Bạn có thể sử dụng lệnh trước đó để truy vấn bảng của mình cho các mục có cùng giá trị biểu thức điều kiện chính. Hãy để chúng tôi tìm kiếm trong bảng “Đơn hàng” của chúng tôi để tìm order_Id từ Darry Tech. Chúng tôi cũng đặt giới hạn 10 mục trên mỗi trang. Một tùy chọn khác cho tham số –limit là sử dụng tham số –page-size cho cùng một mục đích.
Phân trang là thao tác tự động trong AWS CLI đối với các mục dưới 1 MB dữ liệu. Bạn có thể thêm một phím bắt đầu độc quyền vào lệnh nếu bạn muốn truy vấn của mình bắt đầu từ một thứ tự cụ thể.
Câu trả lời trông như thế này:
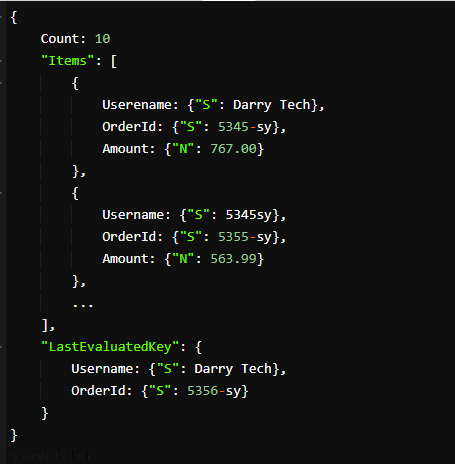
Kết quả được cung cấp hiển thị 10 Darry Tech trên trang đầu tiên. Bạn có thể sử dụng các giá trị LastEvaluatedKey để nhận thêm đơn đặt hàng khớp với các giá trị khóa biểu thức của tìm kiếm của bạn để tạo truy vấn mới. Yêu cầu truy vấn mới chứa các giá trị LastEvaluatedKey trong tham số ExclusiveStartKey.
Một ví dụ về cú pháp được hiển thị trong phần sau:
truy vấn aws dynamodb \--table-name Ví dụTable \
--key-điều kiện-biểu thức 'Khóa phân vùng = :pk \
--biểu thức-thuộc tính-giá trị '{' : pk ':{' S ': Darry Tech' \
--giới hạn 10 \
--exclusive-start-key '{' khóa phân vùng ':{' S ': Darry Tech' }, 'Khóa sắp xếp' :{ 'S' : '5356' }} '
Lệnh trước tạo ra các đơn đặt hàng bù trừ tiếp theo trong trang tiếp theo, bắt đầu với ID đơn đặt hàng có khóa chính được chỉ định, tức là {“PartitionKey”:{“S”: Darry Tech”},”SortKey”:{“S”: ”5356-sy”}}.
2. Phân trang trong khi thao tác quét
Cũng có thể sử dụng phân trang cho các hoạt động quét. Mọi thứ hoạt động giống như với các lệnh truy vấn. Tuy nhiên, bạn cần sử dụng thuộc tính filter-expression. Lệnh trông giống như những gì chúng ta có ở đây:
quét aws dynamodb \--table-name MyTable \
--filter-biểu thức 'Tên thuộc tính = :giá trị' \
--biểu thức-thuộc tính-giá trị '{':value':{'S':'ABC123'}}' \
--giới hạn hai mươi \
--exclusive-start-key '{'Khóa phân vùng':{'S':'ABC123'},'SortKey':{'S':'XYZ987'}}'
Lệnh trước đó rút tối đa 20 mục trên mỗi trang khỏi bảng MyTable, bắt đầu với mục có khóa chính là {“PartitionKey”: “ABC123”, “SortKey”: “XYZ987”}. Nó lọc các kết quả để chỉ bao gồm các mục mà thuộc tính AttributeName có giá trị “ABC123”.
Trong phản hồi, các Khóa được đánh giá lần cuối trường chứa khóa chính của mục cuối cùng trong tập kết quả. Bạn có thể sử dụng giá trị này như là Độc quyềnStartKey trong một tiếp theo quét thao tác để truy xuất trang kết quả tiếp theo.
Phần kết luận
Phân trang trong DynamoDB cải thiện khả năng quản lý dữ liệu. Tuy nhiên, điều quan trọng là phải biết liệu hệ thống của bạn có được hưởng lợi từ việc phân trang hay không. Cần phải sử dụng phân trang nếu bạn có một danh sách dài các mục trong một ứng dụng. Mặc dù hình minh họa được cung cấp tập trung vào lệnh gọi AWS CLI, nhưng bạn cũng có thể sử dụng tính năng phân trang với AWS SDK chẳng hạn như Boto3 của Python hoặc bất kỳ SDK nào mà bạn thích.