Amazon Redshift là một giải pháp đám mây do AWS cung cấp nhằm đáp ứng mục đích của kho dữ liệu. Kho dữ liệu là một không gian lớn trên đám mây lưu trữ lượng dữ liệu khổng lồ. Sự khác biệt giữa kho dữ liệu và cơ sở dữ liệu là kho dữ liệu không chỉ lưu trữ dữ liệu hiện tại mà còn toàn bộ lịch sử của dữ liệu.
Bài viết này sẽ tìm hiểu về Amazon Redshift by AWS và các loại dữ liệu mà dịch vụ này hỗ trợ.
Amazon RedShift là gì?
Đó là một giải pháp đám mây để lưu trữ dữ liệu dựa trên 'PostgreSQL' . Nó sử dụng một công nghệ gọi là 'Xử lý song song hàng loạt (MPP)' để xử lý hàng petabyte dữ liệu với tốc độ cực nhanh. Điều này cung cấp một giải pháp dễ dàng để dự đoán thời gian thực dựa trên dữ liệu lịch sử và giải pháp phát trực tuyến.
Hình dưới đây cho thấy cơ chế hoạt động của Amazon Redshift:
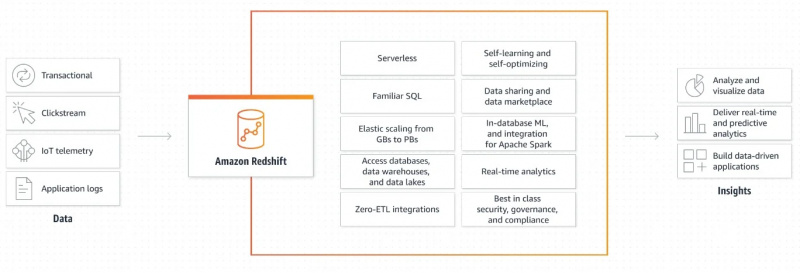
Phần giải thích bằng đồ họa về cách thức hoạt động của Amazon Redshift rất đơn giản và rõ ràng. Nó cung cấp cho chúng tôi thông tin về cách dữ liệu được truy xuất và xử lý thêm để tạo đầu ra và tạo các ứng dụng dựa trên dữ liệu.
Kiến trúc kho dữ liệu của Amazon Redshift cũng có thể được nhìn thấy trong hình dưới đây:
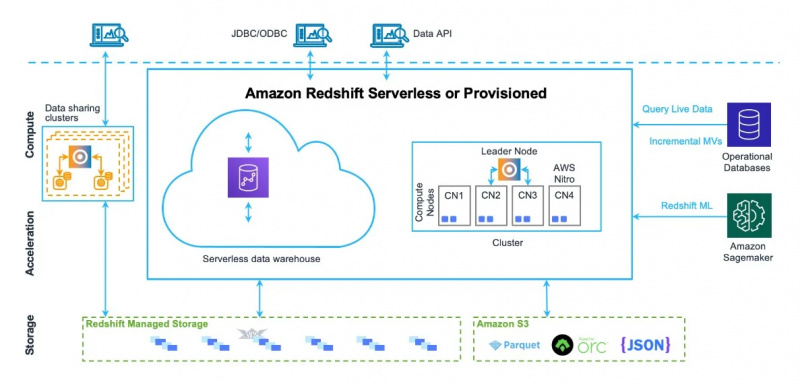
Bây giờ, chúng ta sẽ chuyển sang sử dụng và các tính năng của dịch vụ này.
Đặc trưng
Như đã đề cập, Amazon Redshift dựa trên PostgreSQL và sử dụng công nghệ có tên là Xử lý song song hàng loạt cho phép nó xử lý hàng petabyte dữ liệu ngay lập tức. Do đó, Redshift cung cấp một số tính năng và cách sử dụng tốt. Một số tính năng dưới đây:
- Bảo mật và mã hóa dữ liệu.
- Phân tích kinh doanh.
- Hỗ trợ ứng dụng dựa trên dữ liệu.
- Phân tích tiên đoán.
- Tự động lặp lại nhiệm vụ.
- Mở rộng dữ liệu đồng thời.
- Kho dữ liệu.
Một số tính năng bổ sung của dịch vụ này có thể được nhìn thấy trong hình dưới đây:
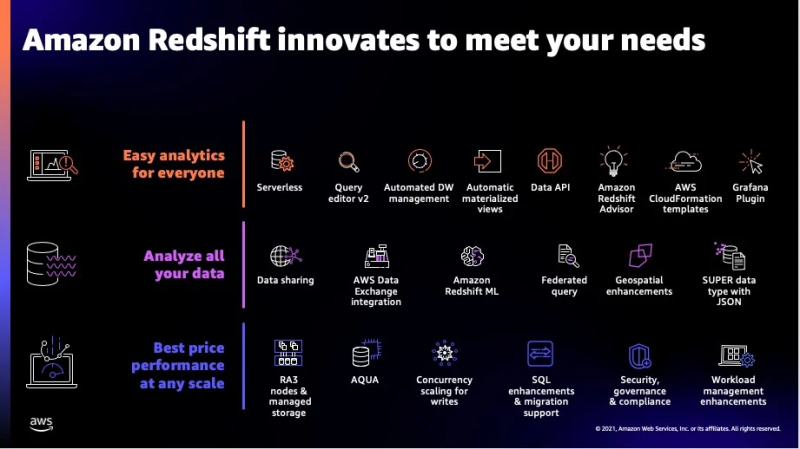
Đây là hầu hết các tính năng mà Redshift cung cấp và bây giờ chúng tôi sẽ chuyển sang các loại dữ liệu được dịch vụ này hỗ trợ.
Loại dữ liệu
Amazon Redshift là một giải pháp lưu trữ dữ liệu với rất nhiều tính năng. Nó hỗ trợ cả kiểu dữ liệu có cấu trúc và phi cấu trúc. Vì nó dựa trên PostgreSQL, dữ liệu có thể được thao tác thông qua các truy vấn SQL đơn giản.
Bây giờ, một câu hỏi khác được đặt ra, tức là các định dạng dữ liệu này khác nhau như thế nào? Hãy để chúng tôi thảo luận về hai định dạng dữ liệu.
Dữ liệu có cấu trúc
Loại dữ liệu có định dạng cao, dễ dàng dịch bằng thuật toán máy học được gọi là dữ liệu có cấu trúc. Cơ sở dữ liệu SQL hoạt động với dữ liệu có cấu trúc. Dữ liệu có cấu trúc ở dạng bảng, chẳng hạn như dữ liệu được sử dụng bởi cơ sở dữ liệu quan hệ
Một trong những hệ quản trị cơ sở dữ liệu SQL được sử dụng rộng rãi là MYSQL. Kiến trúc của nó có thể được nhìn thấy bên dưới trong hình đã cho:
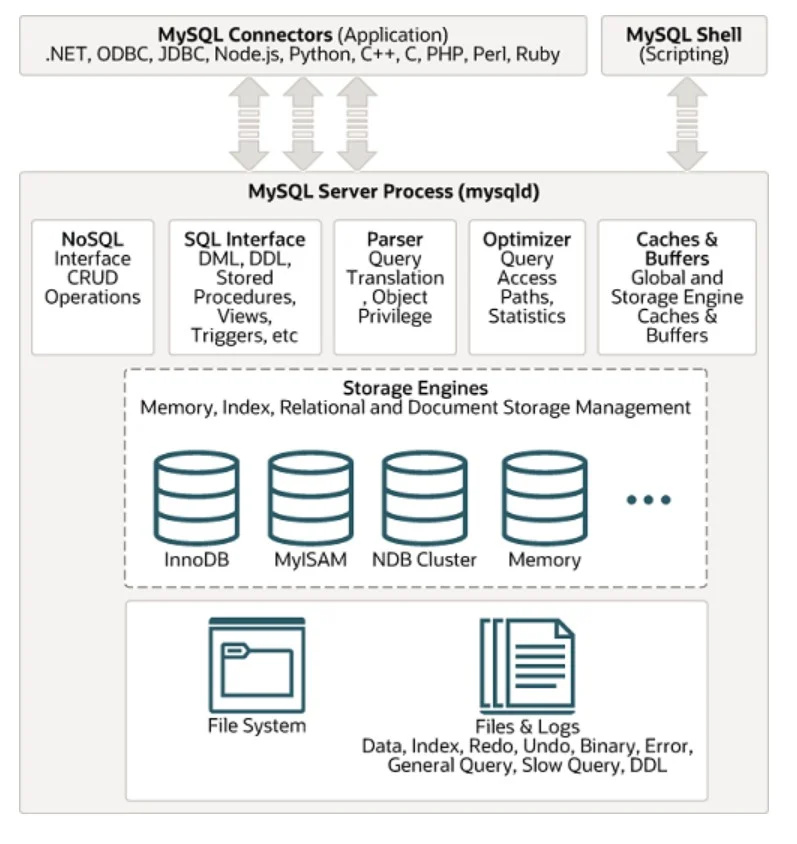
Dữ liệu phi cấu trúc
Dữ liệu phi cấu trúc ít mẫu hơn và ít định dạng dữ liệu hơn, chẳng hạn như dữ liệu được sử dụng trong cơ sở dữ liệu không liên quan. MongoDB là một cơ sở dữ liệu phi quan hệ nổi tiếng. Truy vấn SQL không hoạt động trên cơ sở dữ liệu không quan hệ, vì vậy những cơ sở dữ liệu này còn được gọi là cơ sở dữ liệu NoSQL.
Như đã đề cập, MongoDB là một hệ thống quản lý cơ sở dữ liệu phi cấu trúc và kiến trúc của nó có thể được nhìn thấy bên dưới trong hình đã cho:
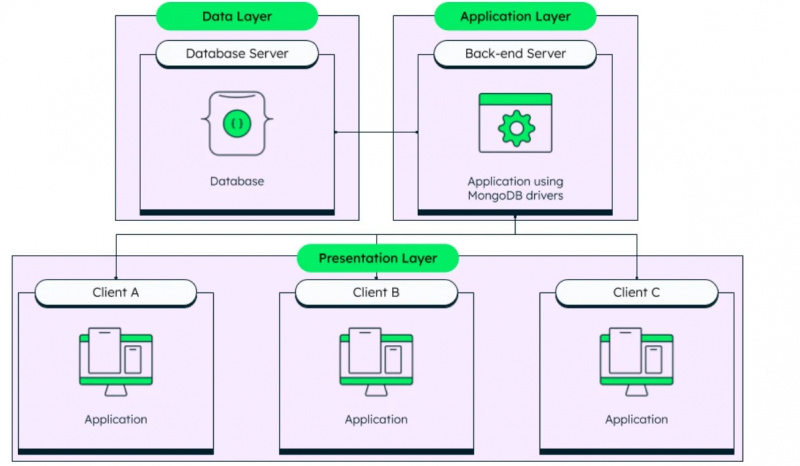
Chúng ta đã xem qua hai loại dữ liệu cơ bản được sử dụng trong cơ sở dữ liệu và bây giờ chúng ta sẽ chuyển sang các loại dữ liệu thực tế được Amazon Redshift hỗ trợ. Các kiểu dữ liệu này là:
- Dữ liệu số
- Dữ liệu ký tự
- Dữ liệu ngày giờ
- Dữ liệu Boolean
- Dữ liệu HLLSKETCH
- Siêu dữ liệu
- Dữ liệu THAY THẾ
Hãy để chúng tôi thảo luận về các loại dữ liệu này:
Dữ liệu số
Loại dữ liệu này là tự giải thích. Nó hỗ trợ dữ liệu ở dạng số nguyên, số thập phân, dấu phẩy động và các kiểu dữ liệu số khác.
Các đặc điểm của kiểu dữ liệu số nguyên có thể được nhìn thấy trong hình dưới đây:
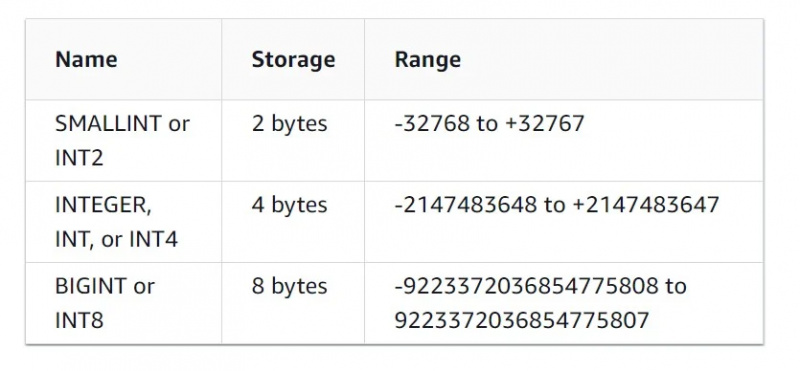
Kiểu dữ liệu thập phân lưu trữ dữ liệu dựa trên độ chính xác từ người dùng. Đặc điểm của nó như sau:

Dữ liệu ký tự
Kiểu dữ liệu CHAR và VARCHAR thuộc danh mục kiểu dữ liệu dựa trên ký tự. NCHAR và NVARCHAR cũng là kiểu dữ liệu kiểu ký tự. Không giống như CHAR và VARCHAR, hai kiểu dữ liệu này lưu trữ các ký tự Unicode có độ dài cố định. Chúng ta hãy xem xét các thuộc tính của các kiểu dữ liệu này, chẳng hạn như:
- CHAR, CHARACTER, NCHAR có phạm vi 4KB.
- VARCHAR, NVARCHAR có phạm vi 64KB.
- BPCHAR có phạm vi 256 Byte.
- VĂN BẢN có phạm vi 260 Byte.
Dữ liệu ngày giờ
Các kiểu dữ liệu ngày giờ là NGÀY, GIỜ, TIMETZ,TIMESTAMP, TIMESTAMPTZ. Các khả năng chức năng của các kiểu dữ liệu này như sau:
- DATE chỉ lưu trữ ngày theo lịch.
- TIME lưu trữ thời gian mà không cần tham chiếu đến bất kỳ múi giờ nào. Đó là UTC, theo mặc định.
- TIMETZ lưu trữ thời gian theo múi giờ. Theo mặc định, đó là UTC trong cả bảng người dùng và bảng hệ thống.
- DẤU THỜI GIAN không chỉ bao gồm thời gian mà còn cả ngày tháng. Theo mặc định, đó là UTC trong cả bảng người dùng và bảng hệ thống.
- TIMESTAMPTZ không chỉ bao gồm thời gian mà còn cả ngày tháng. Theo mặc định, đó là UTC chỉ trong các bảng người dùng.
Dữ liệu Boolean
Kiểu dữ liệu Boolean là kiểu dữ liệu nhị phân, có nghĩa là chỉ có hai giá trị. Bảng đặc điểm cho kiểu dữ liệu Boolean được đưa ra trong hình bên dưới:
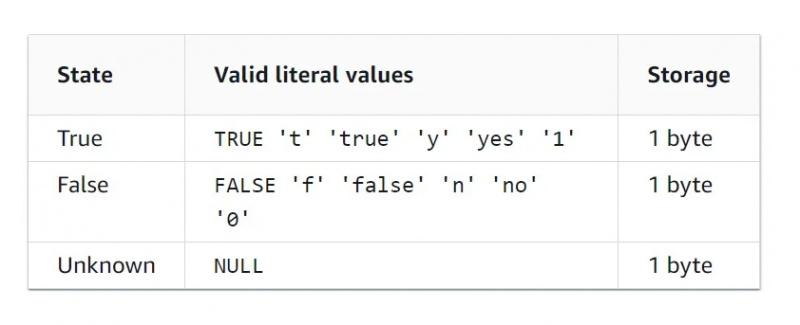
Dữ liệu HLLSKETCH
Kiểu dữ liệu này được sử dụng để lưu trữ các bản phác thảo. Dịch chuyển đỏ có thể biểu diễn các bản phác thảo ở dạng thưa thớt hoặc dày đặc. Các bản phác thảo bắt đầu thưa thớt và dần dần trở nên dày đặc khi định dạng dày đặc mang lại hiệu quả cao hơn bằng cách nhấp vào liên kết.
Siêu dữ liệu
Loại dữ liệu này xử lý dữ liệu phi cấu trúc có thể ở dạng mảng, cấu trúc lồng nhau hoặc JSON. Không có mô hình hoặc định dạng của dữ liệu. Người dùng có thể khám phá thêm thông tin bằng cách điều hướng liên kết.
Dữ liệu THAY THẾ
Kiểu dữ liệu này cũng lưu trữ các ký tự. Tuy nhiên, chiều dài bị hạn chế. Amazon Redshift cho phép truyền dữ liệu VARBYTE vào bất kỳ dữ liệu kiểu số nguyên hoặc kiểu ký tự nào. Để biết thêm thông tin về kiểu dữ liệu này, hãy theo liên kết bên dưới.
Đây là tất cả những gì có về Amazon Redshift và các loại dữ liệu mà nó hỗ trợ.
Phần kết luận
Amazon Redshift là một dịch vụ AWS ở dạng cơ bản phục vụ mục đích của kho dữ liệu nhưng là một giải pháp rất mạnh mẽ và đặc trưng để phân tích và dự đoán. Bài viết này đã thảo luận về Redshift và các loại dữ liệu mà dịch vụ này hỗ trợ. Các loại dữ liệu này đã được giải thích ngắn gọn cùng với các đặc điểm của chúng.